1. Infrastructure
This specification depends on the Infra Standard. [INFRA]
2. Introduction
2.1. Use cases
2.1.1. Web text references
The core use case for text fragments is to allow URLs to serve as an exact text reference across the web. For example, Wikipedia references could link to the exact text they are quoting from a page. Similarly, search engines can serve URLs that direct the user to the answer they are looking for in the page rather than linking to the top of the page.2.1.2. User sharing
With text directives, browsers may implement an option to 'Copy URL to here' when the user opens the context menu on a text selection. The browser can then generate a URL with the text selection appropriately specified, and the recipient of the URL will have the specified text conveniently indicated. Without text fragments, if a user wants to share a passage of text from a page, they would likely just copy and paste the passage, in which case the receiver loses the context of the page.2.2. Link Lifetime
This specification attempts to maximize the useful lifetime of text directive links, for example, by using the actual text content as the URL payload, and allowing a fallback element-id fragment. However, pages on the web often update and change their content. As such, links like this may "rot" in that the text content they point to no longer exists on the destination page.
Text directive links can be useful despite this problem. In user sharing use cases, the link is often transient, intended to be used only within a short time of sending. For longer duration use cases, such as references and web page links, text directives are still valuable since they degrade gracefully into an ordinary link. Additionally, the presence of a stale text directive can be useful information to surface to a user, to help them understand the link creator’s original intent and that the page content may have changed since the link was created.
See § 4 Generating Text Fragment Directives for best practices on how to create robust text directive links.
3. Description
3.1. Indication
This specification intentionally doesn’t define what actions a user agent takes to "indicate" a text match. There are different experiences and trade-offs a user agent could make. Some examples of possible actions:
-
Providing visual emphasis or highlight of the text passage
-
Automatically scrolling the passage into view when the page is navigated
-
Activating a UA’s find-in-page feature on the text passage
-
Providing a "Click to scroll to text passage" notification
-
Providing a notification when the text passage isn’t found in the page
3.2. Syntax
A text directive is specified in the fragment directive (see § 3.3 The Fragment Directive) with the following format:
#:~:text=[prefix-,]start[,end][,-suffix]
context |--match--| context
(Square brackets indicate an optional parameter)
The text parameters are percent-decoded before matching. Dash (-), ampersand (&), and comma (,) characters in text parameters are percent-encoded to avoid being interpreted as part of the text directive syntax.
The only required parameter is start. If only start is specified, the
first instance of this exact text string is the target text.
#:~:text=an%20example%20text%20fragment indicates that the
exact text "an example text fragment" is the target text. If the end parameter is also specified, then the text directive refers to a
range of text in the page. The target text range is the text range starting at
the first instance of start, until the first instance of end that
appears after start. This is equivalent to specifying the entire text range
in the start parameter, but allows the URL to avoid being bloated with a
long text directive.
#:~:text=an%20example,text%20fragment indicates that the first
instance of "an example" until the following first instance of "text fragment"
is the target text. 3.2.1. Context Terms
The other two optional parameters are context terms. They are specified by the
dash (-) character succeeding the prefix and preceding the suffix, to
differentiate them from the start and end parameters, as any
combination of optional parameters can be specified.
Context terms are used to disambiguate the target text fragment. The context terms can specify the text immediately before (prefix) and immediately after (suffix) the text fragment, allowing for whitespace.
The context terms are not part of the targeted text fragment and are not visually indicated.
#:~:text=this%20is-,an%20example,-text%20fragment would match
to "an example" in "this is an example text fragment", but not match to "an
example" in "here is an example text". 3.2.2. BiDi Considerations
Since URL strings are ASCII encoded, they provide no built-in support for bi-directional text. However, the content that we wish to target on a page can be LTR (left-to-right), RTL (right-to-left) or both (Bidirectional/BiDi). This section provides an intuitive description the behavior implicitly described by the normative sections further in this spec.
The characters of each term in the text fragment are in logical order, that is, the order in which a native reader would read them in (and also the order in which characters are stored in memory).
Similarly, the prefix and start terms identify
text coming before another term in logical order, while suffix and end follow other terms in logical order.
Note: user agents can visually render URLs in a manner friendlier to a native reader, for example, by converting the displayed string to Unicode. However, the string representation of a URL remains plain ASCII characters.
مِصر (Egypt, in Arabic),
that’s preceeded by البحرين (Bahrain, in Arabic). We would
first percent encode each term:
مِصر becomes "%D9%85%D8%B5%D8%B1" (Note: UTF-8 character
[0xD9,0x85] is the first (right-most) character of the Arabic word.)
البحرين becomes "%D8%A7%D9%84%D8%A8%D8%AD%D8%B1%D9%8A%D9%86"
The text fragment would then become:
:~:text=%D8%A7%D9%84%D8%A8%D8%AD%D8%B1%D9%8A%D9%86-,%D9%85%D8%B5%D8%B1
When displayed in a browser’s address bar, the browser can visually render the text in its natural RTL direction, appearing to the user:
:~:text=البحرين-,مِصر
3.3. The Fragment Directive
To avoid compatibility issues with usage of existing URL fragments, this spec introduces the concept of a fragment directive. It is the portion of the URL fragment that follows the fragment directive delimiter and may be null if the delimiter does not appear in the fragment.
The fragment directive delimiter is the string ":~:", that is the three consecutive code points U+003A (:), U+007E (~), U+003A (:).
The fragment directive is parsed and processed into individual directives, which are instructions to the user agent to perform some action. Multiple directives may appear in the fragment directive.
https://example.com#:~:text=foo&text=bar&unknownDirective
Contains 2 text directives and one unknown directive.
To prevent impacting page operation, it is stripped from script-accessible APIs to prevent interaction with author script. This also ensures future directives can be added without web compatibility risk.
3.3.1. Extracting the fragment directive
This section describes the mechanism by which the fragment directive is hidden from script and how it fits into HTML § 7.4 Navigation and session history.
-
Session history entries now include a new "directive state" item
-
All new entries are created with a directive state with an empty value. If the new URL includes a fragment directive it will be written to the state’s value (otherwise it remains null).
-
Any time a URL potentially including a fragment directive is written to a session history entry, extract the fragment directive from the URL and store it in a directive state item of the entry. There are four such points where a URL can potentially include a directive:
-
In the "navigate" steps for typical cross-document navigations
-
In the "navigate to a fragment" steps for fragment based same-document navigations
-
In the "URL and history update steps" for synchronous updates such as pushState/replaceState.
-
In the "create navigation params by fetching" steps for URLs coming from a redirect.
-
-
Same-document navigations that change only the fragment, and the new URL doesn’t specify a directive, will create an entry whose directive state refers to the previous entry’s directive state.
In HTML § 7.4.1 Session history, define directive state:
Monkeypatching HTML § 7.4.1 Session history:
directive state holds the value of the fragment directive at the time the session history entry was created and is used to invoke directives, such as text highlighting, whenever the entry is traversed. It has:
value, the fragment directive ASCII string or null, initially null.
A directive state may be shared by multiple session history entries.
The fragment directive is removed from the URL before the URL is set to the session history entry. It is instead stored in the directive state. This prevents it from being visible to script APIs so that a directive can be specified without interfering with a page’s operation.
The fragment directive is stored in the directive state object, rather than a raw string, since the same directive state can be shared across multiple contiguous session history entries. On a traversal, the directive is only processed (i.e. search text and highlight) if the directive state has changed between two entries.
To the definition of session history entry, add:
Monkeypatching HTML § 7.4.1.1 Session history entries:
A session history entry is a struct with the following items:
...
persisted user state, which is implementation-defined, initially null
directive state, a directive state, initially a new directive state
Add a helper algorithm for removing and returning a fragment directive string from a URL:
Monkeypatching [HTML]:
This algorithm makes a URL’s fragment end at the fragment directive delimiter. The returned fragment directive includes all characters that follow the delimiter but does not include the delimiter.TODO: If a URL’s fragment ends with ':~:' (i.e. empty directive), this will return null which is treated as the URL not specifying an explicit directive (and avoids clobbering an existing one. But maybe in this case we should return the empty string? That way a page can explicitly clear directives/highlights by navigating/pushState to '#:~:'.To remove the fragment directive from a URL url, run these steps:
Let raw fragment be equal to url’s fragment.
Let fragment directive be null.
If raw fragment is non-null and contains the fragment directive delimiter as a substring:
Let position be the position variable pointing to the first code point of the first instance, if one exists, of the fragment directive delimiter in raw fragment, or past the end of raw fragment otherwise.
Let new fragment be the code point substring by positions of raw fragment from the start of raw fragment to position.
Advance position by the code point length of the fragment directive delimiter.
If position does not point past the end of raw fragment:
Set fragment directive to the code point substring to the end of the string raw fragment starting from position
Set url’s fragment to new fragment.
Return fragment directive.
https://example.org/#test:~:text=foowill be parsed such that the fragment is the string "test" and the fragment directive is the string "text=foo".
The next four monkeypatches modify the creation of a session history entry, where the URL might contain a fragment directive, to remove the fragment directive and store it in the directive state.
In the definition of navigate:
Monkeypatching HTML § 7.4.2.2 Beginning navigation:
To navigate a navigable navigable to a URL url...:
...
- Set navigable’s ongoing navigation to navigationId.
If url’s scheme is "javascript", then...
In parallel, run these steps:
...
- If url is about:blank, then set documentState’s origin to documentState’s initiator origin.
Otherwise, if url is about:srcdoc, then set documentState’s origin to navigable’s parent’s active document’s origin.
Let historyEntry be a new session history entry, with its URL set to url and its document state set to documentState.- Let fragment directive be the result of running remove the fragment directive on url.
Let directive state be a new directive state with value set to fragment directive.
Let historyEntry be a new session history entry, with its URL set to url, its document state set to documentState, and its directive state set to directive state.
Let navigationParams be null.
...
In the definition of navigate to a fragment:
Monkeypatching HTML § 7.4.2.3.3 Fragment navigations:
To navigate to a fragment given navigable navigable, ...:
Let directive state be navigable’s active session history entry’s directive state.
Let fragment directive be the result of running remove the fragment directive on url.
If fragment directive is not null:
Otherwise, when only the fragment has changed and it did not specify a directive, the active entry’s directive state is reused. This prevents a fragment change from clobbering highlights.
Let directive state be a new directive state with value set to fragment directive.
Let historyEntry be a new session history entry, with
URL url
document state navigable’s active session history entry’s document state
scroll restoration mode navigable’s active session history entry’s scroll restoration mode
directive state directive state
Let entryToReplace be navigable’s active session history entry if historyHandling is "replace", otherwise null.
...
In the definition of URL and history update steps:
Monkeypatching HTML § 7.4.4 Non-fragment synchronous "navigations":
The URL and history update steps, given a Document document, ...:
Let navigable be document’s node navigable.
Let activeEntry be navigable’s active session history entry.
Let fragment directive be the result of running remove the fragment directive on newUrl.
Let historyEntry be a new session history entry, with
URL newUrl
...
directive state activeEntry’s directive state
If document’s is initial about:blank is true, then set historyHandling to "replace".
If historyHandling is "push", then:
Increment document’s history object’s index.
Set document’s history object’s length to its index + 1.
If newUrl does not equal activeEntry’s URL with exclude fragments set to true OR fragment directive is not null, then:
Otherwise, when only the fragment has changed and it did not specify a directive, the active entry’s directive state is reused. This prevents a fragment change from clobbering highlights.
Let historyEntry’s directive state be a new directive state with value set to fragment directive.
Otherwise, if fragment directive is not null, set historyEntry’s directive state's value to fragment directive.
If serializedData is not null, then restore the history object state given document and newEntry.
In the definition of create navigation params by fetching:
Monkeypatching HTML § 7.4.5 Populating a session history entry:
To create navigation params by fetching given a session history entry entry, ...:
Assert: this is running in parallel.
...
- Let currentURL be request’s current URL.
Let commitEarlyHints be null.
While true:
If request’s reserved client is not null and currentURL’s origin is not the same as request’s reserved client’s creation URL’s origin, then:
...
- Set currentURL to locationURL.
Let fragment directive be the result of running remove the fragment directive on locationURL.
Set entry’s URL to currentURL.Set entry’s URL to locationURL.
Set entry’s directive state's value to fragment directive.
If locationURL is a URL whose scheme is not a fetch scheme, then return a new non-fetch scheme navigation params, with initiator origin request’s current URL’s origin
...
Since a Document is populated from a history entry, its URL will not include the
fragment directive. Similarly, since a window’s Location object is a representation of the URL of the active document, all getters on it will show a fragment-directive-stripped
version of the URL.
Additionally, since the HashChangeEvent is fired in response to a changed fragment between URLs of session history entries, hashchange will not be fired if a navigation or traversal changes only the fragment
directive.
Some examples are provided to help clarify various edge cases.
window.location = "https://example.com#page1:~:hello"; console.log(window.location.href); // 'https://example.com#page1' console.log(window.location.hash); // '#page1'
The initial navigation created a new session history entry. The entry’s URL is stripped of the fragment directive: "https://example.com#page1". The entry’s directive state value is set to "hello". Since the document is populated from the entry, web APIs don’t include the fragment directive in URLs.
location.hash = "page2"; console.log(location.href); // 'https://example.com#page2'
A same document navigation changed only the fragment. This adds a new session history entry in the navigate to a fragment steps. However, since only the fragment changed, the new entry’s directive state points to the same state as the first entry, with a value of "bar".
onhashchange = () => console.assert(false, "hashchange doesn’t fire."); location.hash = "page2:~:world"; console.log(location.href); // 'https://example.com#page2' onhashchange = null;
A same document navigation changes only the fragment but includes a fragment directive. Since an explicit directive was provided, the new entry includes its own directive state with a value of "fizz".
The hashchange event is not fired since the page-visible fragment is unchanged; only the fragment directive changed. This is because the comparison for hashchange is done on the URLs in the session history entries, where the fragment directive has been removed.
history.pushState("", "", "page3");
console.log(location.href); // 'https://example.com/page3'
pushState creates a new session history entry for the same document. However, since the non-fragment URL has changed, this entry has its own directive state with value currently null.
For URL objects:
let url = new URL('https://example.com#foo:~:bar');
console.log(url.href); // 'https://example.com#foo:~:bar'
console.log(url.hash); // '#foo:~:bar'
document.url = url;
console.log(document.url.href); // 'https://example.com#foo:~:bar'
console.log(document.url.hash); // '#foo:~:bar'
The <a> or <area> elements:
<a id='anchor' href="https://example.com#foo:~:bar">Anchor</a> <script> console.log(anchor.href); // 'https://example.com#foo:~:bar' console.log(anchor.hash); // '#foo:~:bar' </script>
3.3.2. Applying directives to a document
The section above described how the fragment directive is separated from the URL and stored in a session history entry.
This section defines how and when navigations and traversals make use of history entry’s directive state to apply the directives associated with a session history entry to a Document.
Monkeypatching DOM § 4.5 Interface Document:
Each document has an associated pending text directives which is either null or an list of text directives. It is initially null.
In the definition of update document for history step application:
Monkeypatching HTML § 7.4.6.2 Updating the document:
To update document for history step application given a Document document, a session history entry entry,...
...
- Set document’s history object’s length to scriptHistoryLength
If documentsEntryChanged is true, then:
Let oldURL be document’s latest entry’s URL.
Let fragment directive be entry’s directive state's value.
Set document’s pending text directives to the result of parsing fragment directive.
Set document’s latest entry to entry
...
3.3.3. Fragment directive grammar
Note: This section is non-normative.
Note: This grammar is provided as a convenient reference; however, the rules and steps for parsing are specified imperatively in the § 3.4 Text Directives section. Where this grammar differs in behavior from the steps of that section, the steps there are to be taken as the authoritative source of truth.
The FragmentDirective can contain multiple directives split by the "&" character. Currently this means we allow multiple text directives to enable multiple indicated strings in the page, but this also allows for future directive types to be added and combined. For extensibility, we do not fail to parse if an unknown directive is in the &-separated list of directives.
A string is a valid fragment directive if it matches the EBNF (Extended Backus-Naur Form) production:
-
FragmentDirective::= -
(TextDirective | UnknownDirective) ("&" FragmentDirective)? -
TextDirective::= -
"text="CharacterString -
UnknownDirective::= -
CharacterString - TextDirective -
CharacterString::= -
(ExplicitChar | PercentEncodedByte)* -
ExplicitChar::= -
[a-zA-Z0-9] | "!" | "$" | "'" | "(" | ")" | "*" | "+" | "." | "/" | ":" | ";" | "=" | "?" | "@" | "_" | "~" | "," | "-"An ExplicitChar may be any URL code point other than "&".
A TextDirective is considered valid if it matches the following production:
ValidTextDirective::="text=" TextDirectiveParametersTextDirectiveParameters::=-
(TextDirectivePrefix ",")? TextDirectiveString ("," TextDirectiveString)? ("," TextDirectiveSuffix)? TextDirectivePrefix::=TextDirectiveString"-"TextDirectiveSuffix::="-"TextDirectiveStringTextDirectiveString::=(TextDirectiveExplicitChar | PercentEncodedByte)+TextDirectiveExplicitChar::=-
[a-zA-Z0-9] | "!" | "$" | "'" | "(" | ")" | "*" | "+" | "." | "/" | ":" | ";" | "=" | "?" | "@" | "_" | "~"A TextDirectiveExplicitChar is any URL code point that is not explicitly used in the FragmentDirective or ValidTextDirective syntax, that is "&", "-", and ",". If a text fragment refers to a "&", "-", or "," character in the document, it will be percent-encoded in the fragment. PercentEncodedByte::="%" [a-zA-Z0-9][a-zA-Z0-9]
3.4. Text Directives
A text directive is a kind of directive representing a range of text to be indicated to the user. It is a struct that consists of four strings: start, end, prefix, and suffix. start is required to be non-null. The other three items may be set to null, indicating they weren’t provided. The empty string is not a valid value for any of these items.
See § 3.2 Syntax for the what each of these components means and how they’re used.
-
If term is null, return null.
-
Assert: term is an ASCII string.
-
Let decoded bytes be the result of percent-decoding term.
-
Return the result of running UTF-8 decode without BOM on decoded bytes.
This algorithm takes a single text directive value string as input (e.g. "prefix-,foo,bar") and attempts to parse the string into the components of the directive (e.g. ("prefix", "foo", "bar", null)). See § 3.2 Syntax for the what each of these components means and how they’re used.
Returns null if the input is invalid. Otherwise, returns a text directive.
-
Let prefix, suffix, start, end, each be null.
-
Assert: text directive value is an ASCII string with no code points in the fragment percent-encode set and no instances of U+0026 (&).
-
Let tokens be a list of strings that result from strictly splitting text directive value on U+002C (,).
-
If tokens has size less than 1 or greater than 4, return null.
-
If the first item of tokens ends with U+002D (-):
-
If the last item of tokens starts with U+002D (-):
-
If tokens has size greater than 2, return null.
-
Set start to the first item in tokens.
-
Remove the first item in tokens.
-
If start is the empty string or contains any instances of U+002D (-), return null.
-
If tokens is not empty:
-
Set end to the first item in tokens.
-
If end is the empty string or contains any instances of U+002D (-), return null.
-
-
Return a new text directive, with
- prefix
- The percent-decoding of prefix
- start
- The percent-decoding of start
- end
- The percent-decoding of end
- suffix
- The percent-decoding of suffix
To parse the fragment directive, an an ASCII string fragment directive, run these steps:
-
Let directives be the result of strictly splitting fragment directive on U+0026 (&).
-
Let output be an initially empty list of text directives.
-
For each string directive in directives:
-
If directive does not start with "
text=", then continue. -
Let text directive value be the code point substring from 5 to the end of directive.
Note: this may be the empty string. -
Let parsed text directive be the result of parsing text directive value.
-
If parsed text directive is non-null, append it to output.
-
-
Return output.
3.4.1. Invoking Text Directives
This section describes how text directives in a document’s pending text directives are processed and invoked to cause indication of the relevant text passages.
-
Modify the indicated part processing model to try processing pending text directives into a range that will be returned as the indicated part.
-
Modify "scrolling to a fragment" to correctly scroll and set the Document’s target element in the case of a range based indicated part.
-
Ensure pending text directives is reset to null when the user agent has finished the fragment search for the current navigation/traversal.
-
If the user agent finishes searching for a text directive, ensure it tries the regular fragment as a fallback.
In indicated part, enable a fragment to indicate a range. Make the following changes:
Monkeypatching HTML § 7.4.6.3 Scrolling to a fragment:
For an HTML document document, the following processing model must be followed to determine its indicated part:
Let text directives be the document’s pending text directives.
If text directives is non-null then:
Let ranges be a list that is the result of running the invoke text directives steps with text directives and the document.
If ranges is non-empty, then:
Let firstRange be the first item of ranges.
Visually indicate each range in ranges in an implementation-defined way. The indication must not be observable from author script. See § 3.7 Indicating The Text Match.
The first range in ranges is the one that gets scrolled into view but all ranges should be visually indicated to the user.Set firstRange as document’s indicated part, return.
Let fragment be document’s URL’s fragment.
If fragment is the empty string, then return the special value top of the document.
Let potentialIndicatedElement be the result of finding a potential indicated element given document and fragment.
...
In scroll to the fragment, handle an indicated part that is a range and also prevent fragment scrolling if the force-load-at-top policy is enabled. Make the following changes:
Monkeypatching HTML § 7.4.6.3 Scrolling to a fragment:
If document’s indicated part is null, then set document’s target element to null.
Otherwise, if document’s indicated part is top of the document, then:
Set document’s target element to null.
Scroll to the beginning of the document for document.
Return.
Otherwise:
Assert: document’s indicated part is an element or it is a range.
Let scrollTarget be document’s indicated part.
Let target be scrollTarget.
If target is a range, then:
Set target to be the first common ancestor of target’s start node and end node.
While target is non-null and is not an element, set target to target’s parent.
What should be set as target if inside a shadow tree? #190Assert: target is an element.
Set document’s target element to target.
Run the ancestor details revealing algorithm on target.
Run the ancestor hidden-until-found revealing algorithm on target.
These revealing algorithms currently wont work well since target could be an ancestor or even the root document node. Issue #89 proposes restricting matches tocontain:style layoutblocks which would resolve this problem.Let blockPosition be "center" if scrollTarget is a range, "start" otherwise.
Scrolling to a text directive centers it in the block flow direction.Scroll target into view, with behavior set to "auto", block set to "start", and inline set to "nearest".- scroll a target into view, with target set to scrollTarget, behavior set to "auto", block set to blockPosition, and inline set to "nearest".
Implementations MAY avoid scrolling to the target if it is produced from a text directive.
Run the focusing steps for target, with the Document’s viewport as the fallback target.
Move the sequential focus navigation starting point to target.
The next two monkeypatches ensure the user agent clears pending text directives when the fragment search is complete. In the case where a text directive search finishes because parsing has stopped, it tries one more search for a non-text directive fragment.
In the definition of try to scroll to the fragment:
Monkeypatching HTML § 7.4.6.3 Scrolling to a fragment:
To try to scroll to the fragment for a Document document, perform the following steps in parallel:
Wait for an implementation-defined amount of time. (This is intended to allow the user agent to optimize the user experience in the face of performance concerns.)
Queue a global task on the navigation and traversal task source given document’s relevant global object to run these steps:
If document has no parser, or its parser has stopped parsing, or the user agent has reason to believe the user is no longer interested in scrolling to the fragment, then abort these steps.- If the user agent has reason to believe the user is no longer interested in scrolling to the fragment, then:
Set pending text directives to null.
Abort these steps.
If the document has no parser, or its parser has stopped parsing, then:
If pending text directives is not null, then:
Set pending text directives to null.
Scroll to the fragment given document.
Abort these steps.
Scroll to the fragment given document.
If document’s indicated part is still null, then try to scroll to the fragment for document. Otherwise, set pending text directives to null.
In the definition of navigate to a fragment:
Monkeypatching HTML § 7.4.2.3.3 Fragment navigations:
To navigate to a fragment given navigable navigable, ...:
...
- Update document for history step application given navigable’s active document, historyEntry, true, scriptHistoryIndex, and scriptHistoryLength.
Scroll to the fragment given navigable’s active document.
- Set navigable’s active document’s pending text directives to null.
Let traversable be navigable’s traversable navigable.
...
Scrolling to the indicated part is only one of several things that happens from "scroll to the fragment". Rename it and related definitions:
Monkeypatching HTML § 7.4.2.3.3 Fragment navigations:
Rename HTML § 7.4.2.3.3 Fragment navigations and related steps to "indicating a fragment" to reflect its broader effects.
3.5. Security and Privacy
3.5.1. Motivation
Care must be taken when implementing text directive so that it cannot be used to exfiltrate information across origins. Scripts can navigate a page to a cross-origin URL with a text directive. If a malicious actor can determine that the text fragment was successfully found in victim page as a result of such a navigation, they can infer the existence of any text on the page.
The processing model in the following subsections restricts the feature to mitigate the expected attack vectors. In summary, text directives are restricted to:
-
top level navigables (i.e. no iframes).
-
This isn’t strictly true, Chrome allows this for same-origin initiators. Need to update the spec on this point. [Issue #WICG/scroll-to-text-fragment#240]
-
-
navigations that are the result of a user action
-
in cases where the navigation has a cross-origin initiator, the destination must be opener isolated (i.e. no references to its global objects in other documents)
3.5.2. Scroll On Navigation
A UA may choose to automatically scroll a matched text passage into view. This can be a convenient experience for the user but does present some risks that implementing UAs need to be aware of.
There are known (and potentially unknown) ways a scroll on navigation might be detectable and distinguished from natural user scrolls.
All known cases like this rely on specific circumstances about the target page so don’t apply generally. With additional restrictions about when the text fragment can invoke an attacker is further restricted. Nonetheless, different UAs can come to different conclusions about whether these risks are acceptable. UAs need to consider these factors when determining whether to scroll as part of navigating to a text fragment.
Conforming UAs may choose not to scroll automatically on navigation. Such UAs may, instead, provide UI to initiate the scroll ("click to scroll") or none at all. In these cases UA should provide some indication to the user that an indicated passage exists further down on the page.
The examples above illustrate that in specific circumstances, it can be possible for an attacker to extract 1 bit of information about content on the page. However, care must be taken so that such opportunities cannot be exploited to extract arbitrary content from the page by repeating the attack. For this reason, restrictions based on user activation and browsing context isolation are very important and must be implemented.
However, it also ensures any malicious use is difficult to hide. A browsing context that’s the only one in a group will be a top level browsing context (i.e. a full tab/window).
If a UA does choose to scroll automatically, it must ensure no scrolling is performed while the document is in the background (for example, in an inactive tab). This ensures any malicious usage is visible to the user and prevents attackers from trying to secretly automate a search in background documents.
If a UA chooses not to scroll automatically, it must scroll a fallback element-id into view, if provided, regardless of whether a text fragment was matched. Not doing so would allow detecting the text fragment match based on whether the element-id was scrolled.
3.5.3. Search Timing
A naive implementation of the text search algorithm could allow information exfiltration based on runtime duration differences between a matching and non- matching query. If an attacker could find a way to synchronously navigate to a text directive-invoking URL, they would be able to determine the existence of a text snippet by measuring how long the navigation call takes.
For this reason, the implementation must ensure the runtime of § 3.6 Navigating to a Text Fragment steps does not differ based on whether a match has been successfully found.
This specification does not specify exactly how a UA achieves this as there are multiple solutions with differing tradeoffs. For example, a UA may continue to walk the tree even after a match is found in find a range from a text directive. Alternatively, it may schedule an asynchronous task to find and set the Document's indicated part.
3.5.4. Restricting the Text Fragment
-
Add a boolean
text directive user activationto both Document and Request. This flag is set on a document when created from a user activated navigation and consumed if a text directive is scrolled. If unconsumed, it can be transfered to an outgoing navigation request. This implements the user-activation-through-redirects behavior described in the note below. -
Define a series of checks, performed on a document and the user involvement and initiator origin state of a navigation, to determine whether a text directive should be allowed to perform a scroll.
-
Compute the scroll permission from "finalize a cross document navigation" and from "navigate to a fragment steps" and plumb it through to the "scroll to the fragment" steps where its used to abort a text directive scroll.
Amend the definition of a request and of a Document to include a new boolean text directive user activation field:
Monkeypatching [FETCH]:
A request has an associated boolean text directive user activation, initially false.
Monkeypatching [HTML]:
Each Document has a text directive user activation, which is a boolean, initially false.
text directive user activation provides the necessary user gesture signal to allow a single activation of a text fragment. It is set to true during document loading only if the navigation occurred as a result of a user activation and is propagated across client-side redirects.If a Document's text directive user activation isn’t used to activate a text fragment, it is instead used to set a new navigation request's text directive user activation to true. In this way, a text directive user activation can be propagated from one Document to another across a navigation.
Both Document's text directive user activation and request's text directive user activation are always set to false when used, such that a single user activation cannot be reused to activate more than one text fragment.
This mechanism allows text fragments to activate through a common redirect technique used by many popular web sites. Such sites redirect users to their intended destination by responding with a 200 status code containing script to set the window.location .
Unlike real HTTP (
status 3xx
) redirects, these "client-side"
redirects cannot propagate the fact that the navigation is the result of a
user gesture. The text directive user activation mechanism allows passing
through this specifically scoped user-activation through such navigations.
This means a page is able to programmatically navigate to a text fragment, a
single time, as if it has a user gesture. However, since this resets text fragment user
activation, further text fragment navigations will not activation without a new user gesture.
The following diagram demonstrates how the flag is used to activate a text fragment through a client-side redirect service:
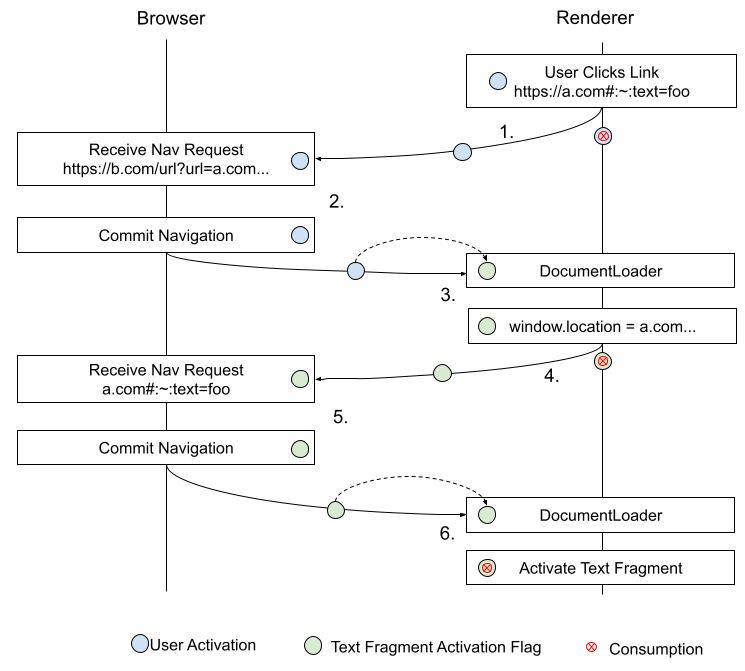
See redirects.md for a more in-depth discussion.
Amend the create navigation params by fetching steps to transfer the active document's text directive user activation value into request’s text directive user activation.
Monkeypatching [HTML]:
Assert: this is running in parallel.
Let documentResource be entry’s document state’s resource.
Let request be a new request, with
- url
- entry’s URL
- ...
- ...
- referrer policy
- entry’s document state’s request referrer policy
- text directive user activation
- navigable’s active document's text directive user activation
Set navigable’s active document's text directive user activation to false.
If documentResource is a POST resource, then:
...
Amend the definition of navigation params to include a new field:
Monkeypatching [HTML]:
- user involvement
- A user navigation involvement value.
Initialize the user involvement value everywhere a navigation params is created. Specifically: initialize it to true in the create navigation params by fetching case:
Monkeypatching [HTML]:
To create navigation params by fetching given a session history entry entry, a navigable navigable, a source snapshot params sourceSnapshotParams, a target snapshot params targetSnapshotParams, a string cspNavigationType, a navigation ID-or-null navigationId, a NavigationTimingType navTimingType, and a user navigation involvement user involvement, perform the following steps. They return a navigation params, a non-fetch scheme navigation params, or null.
Assert: this is running in parallel.
...
- Let resultPolicyContainer be the result of determining navigation params policy container given response’s URL, entry’s document state’s history policy container, sourceSnapshotParams’s source policy container, null, and responsePolicyContainer.
If navigable’s container is an iframe, and response’s timing allow passed flag is set, then set container’s pending resource-timing start time to null.
Return a new navigation params, with
- id
- navigationId
- ...
- ...
- about base URL
- entry’s document state’s about base URL
- user involvement
- user involvement
Amend the create and initialize a Document object steps to compute and store the text directive user activation flag:
Monkeypatching [HTML]:
Process link headers given document, navigationParams’s response, and "pre-media".
navigationParams’s user involvement is "
activation";navigationParams’s user involvement is "
browser UI"; ornavigationParams’s request’s text directive user activation is true.
It’s important that text directive user activation not be copyable so that only one text fragment can be activated per user-activated navigation.Return document.
A text directive allowing MIME type is a MIME type whose essence is
"text/html" or "text/plain".
Note: As noted in scrolling to a fragment, fragment processing is defined individually by each MIME type. As such, the scroll to the fragment steps where text directives are scrolled should only apply to text/html media types. However, in practice, web browsers tend to apply HTML fragment processing to other types, such as text/plain (e.g. add an element with an id to a text/plain document, navigating to the fragment-id causes scrolling). While this is the case, enabling text directives in text/plain documents is useful. Other types are explicitly disallowed to prevent the possibility of XS-Search attacks on potentially sensitive application data (e.g. text/css, application/json, application/javascript, etc.).
Is this valid to say in the HTML spec?
-
If document’s pending text directives field is null or empty, return false.
-
Let is user involved be true if: document’s text directive user activation is true, or user involvement is one of "
activation" or "browser UI"; false otherwise. -
Set document’s text directive user activation to false.
-
If document’s content type is not a text directive allowing MIME type, return false.
-
If user involvement is "
browser UI", return true.If a navigation originates from browser UI, it’s always ok to allow it since it’ll be user triggered and the page/script isn’t providing the text snippet.
Note: The intent in this item is to distinguish cases where the app/page is able to control the URL from those that are fully under the user’s control. In the former we want to prevent scrolling of the text fragment unless the destination is loaded in a separate browsing context group (so that the source cannot both control the text snippet and observe side-effects in the navigation). There are some cases where "browser UI" may be a grey area in this regard. E.g. an "open in new window" context menu item when right clicking on a link.
See sec-fetch-site in [FETCH-METADATA] for a related discussion of how this applies.
-
If is user involved is false, return false.
-
If document’s node navigable has a parent, return false.
-
If initiator origin is non-null and document’s origin is same origin with initiator origin, return true.
-
If document’s browsing context's group's browsing context set has length 1, return true.
i.e. Only allow navigation from a cross-origin element/script if the document is loaded in a noopener context. That is, a new top level browsing context group to which the navigator does not have script access and which can be placed into a separate process. -
Otherwise, return false.
Amend (the already amended, in § 3.4.1 Invoking Text Directives) scroll to the fragment steps to add a new parameter, a boolean allow text directive scroll:
Monkeypatching HTML § 7.4.6.3 Scrolling to a fragment:
To scroll to the fragment given a Document document and boolean allow text directive scroll:
If document’s indicated part is null, then set document’s target element to null.
...
Otherwise:
Assert: document’s indicated part is an element or it is a range.
...
- If target is a range, then:
If allow text directive scroll is false, return.
Set target to be the first common ancestor of target’s start node and end node.
...
Amend the try to scroll to the fragment by adding a boolean flag allow text directive scroll and replacing the steps of the task queued in step 2:
Monkeypatching [HTML]:
To try to scroll to the fragment for a Document document, with boolean allow text directive scroll, perform the following steps in parallel:
Wait for an implementation-defined amount of time. (This is intended to allow the user agent to optimize the user experience in the face of performance concerns.)
Queue a global task on the navigation and traversal task source given document’s relevant global object to run these steps:
If document has no parser, or its parser has stopped parsing, or the user agent has reason to believe the user is no longer interested in scrolling to the fragment, then abort these steps.
Scroll to the fragment given document and allow text directive scroll.
If document’s indicated part is still null, then try to scroll to the fragment for document and allow text directive scroll.
Amend the update document for history step application steps to take a boolean allow text directive scroll and use it when scrolling to a fragment:
Monkeypatching [HTML]:
To update document for history step application given a Document document, a session history entry entry, a boolean doNotReactivate, integers scriptHistoryLength and scriptHistoryIndex, an optional list of session history entries entriesForNavigationAPI, and a boolean allow text directive scroll:
Let documentIsNew be true if document’s latest entry is null; otherwise false.
...
- If documentsEntryChanged is true, then:
Let oldURL be document’s latest entry’s URL.
...
If documentIsNew is true, then:
Try to scroll to the fragment with document and allow text directive scroll.
Amend the apply the history step algorithm to take a boolean allow text directive scroll and pass it through when calling update document for history step application :
Monkeypatching [HTML]:
To apply the history step given a non-negative integer step to a traversable navigable traversable, with boolean checkForCancelation, source snapshot params-or-null sourceSnapshotParams, navigable-or-null initiatorToCheck, user navigation involvement-or-null userInvolvementForNavigateEvents, and boolean allow text directive scroll (default false) perform the following steps. They return "initiator-disallowed", "canceled-by-beforeunload", "canceled-by-navigate", or "applied".
While completedChangeJobs does not equal totalChangeJobs:
...
- Queue a global task on the navigation and traversal task source given navigable’s active window to run the steps:
If changingNavigableContinuation’s update-only is false, then:
...
Activate history entry targetEntry for navigable.
Let updateDocument be an algorithm step which performs update document for history step application given targetEntry’s document, targetEntry, changingNavigableContinuation’s update-only, scriptHistoryLength, scriptHistoryIndex, entriesForNavigationAPI, and allow text directive scroll
If targetEntry’s document is equal to displayedDocument, then perform updateDocument.
Let totalNonchangingJobs be the size of nonchangingNavigablesThatStillNeedUpdates.
Amend the apply the push/replace history step to take and pass allow text directive scrolling to apply the history step:
Monkeypatching [HTML]:
To apply the push/replace history step given a non-negative integer step to a traversable navigable traversable, with boolean allow text directive scroll (default false):Return the result of applying the history step step to traversable given false, null, null, null, allow text directive scroll.
Note: The allow text directive scroll is intentionally not set for traversal and reload cases. This avoids extensive plumbing and checks for initiator origin and user involvement and history scroll state should take precedence anyway. The text directive may still be used as the indicated part of the document so highlights will be restored.
Amend the finalize a cross-document navigation to take a user involvement parameter and compute and pass allow text directive scrolling to apply the push/replace history step:
Monkeypatching [HTML]:
To finalize a cross-document navigation given a navigable navigable, history handling behavior historyHandling, session history entry historyEntry, and user navigation involvement user involvement (default "none"):
Assert: this is running on navigable’s traversable navigable’s session history traversal queue.
...
- Let allow text directive scroll be the result of checking if a text directive can be scrolled, given historyEntry’s document, historyEntry’s document state’s initiator origin, and user involvement
Apply the push/replace history step targetStep to traversable, with allow text directive scroll.
Amend the navigate algorithm to pass user involvement to the finalize a cross-document navigation steps:
Monkeypatching [HTML]:
...
- . In parallel, run these steps:
...
- . Attempt to populate the history entry’s document for historyEntry, given navigable, "navigate", sourceSnapshotParams, targetSnapshotParams, navigationId, navigationParams, cspNavigationType, with allowPOST set to true and completionSteps set to the following step:
Append session history traversal steps to navigable’s traversable to finalize a cross-document navigation given navigable, historyHandling, historyEntry, and userInvolvement.
Amend the Navigate to a fragment algorithm to take an initiator origin parameter and pass the allow text directive scroll flag when scrolling to the fragment:
Monkeypatching [HTML]:
To navigate to a fragment given a navigable navigable, a URL url, a history handling behavior historyHandling, a user navigation involvement userInvolvement, a serialized state-or-null navigationAPIState, navigation ID navigationId, an origin initiator origin:
Let navigation be navigable’s active window’s navigation API.
...
- Update document for history step application given navigable’s active document, historyEntry, true, scriptHistoryIndex, and scriptHistoryLength.
Update the navigation API entries for a same-document navigation given navigation, historyEntry, and historyHandling.
Let allow text directive scroll be the result of checking if a text directive can be scrolled, given navigable’s active document, initiator origin, and userInvolvement
Scroll to the fragment given navigable’s active document, and allow text directive scroll.
Amend the navigate algorithm to pass the initiator origin when performing a fragment navigation:
Monkeypatching [HTML]:
If the navigation must be a replace given url and navigable’s active document, then set historyHandling to "replace".
If all of the following are true:
documentResource is null;
response is null;
url equals navigable’s active session history entry’s URL with exclude fragments set to true; and
url’s fragment is non-null,
then:
Navigate to a fragment given navigable, url, historyHandling, userInvolvement, navigationAPIState, navigationId, and initiatorOriginSnapshot
Let navigation be navigable’s active window’s navigation API.
3.5.5. Restricting Scroll on Load
This section defines how the force-load-at-top policy is used to prevent all
types of scrolling when loading a new document, including but not limited to
text directives.
Need to decide how force-load-at-top interacts with the Navigation API. [Issue #WICG/scroll-to-text-fragment#242]
Amend the restore persisted state steps to take a new boolean parameter which suppresses scroll restoration:
Monkeypatching [HTML]:
To restore persisted state from a session history entry entry , and boolean suppressScrolling:
If entry’s scroll restoration mode is "auto", suppressScrolling is false, and entry’s document’s relevant global object’s navigation API’s suppress normal scroll restoration during ongoing navigation is false, then restore scroll position data given entry.
...
Amend the update document for history step application steps
to check the force-load-at-top policy and avoid scrolling in a new document
if it’s set.
Monkeypatching [HTML]:
...
- Set document’s history object’s length to scriptHistoryLength.
Let scrollingBlockedInNewDocument be the result of getting the policy value for
force-load-at-topfor document.If documentsEntryChanged is true, then:
Let oldURL be document’s latest entry’s URL.
...
- If documentIsNew is false, then:
Update the navigation API entries for a same-document navigation given navigation, entry, and "traverse".
Fire an event named popstate...
Restore persisted state given entry and suppressScrolling set to false.
If oldURL’s fragment is not equal to...
Otherwise,
Assert: entriesForNavigationAPI is given.
Restore persisted state given entry and scrollingBlockedInNewDocument.
Initialize the navigation API entries for a new document given navigation, entriesForNavigationAPI, and entry.
If documentIsNew is true, then:
If scrollingBlockedInNewDocument is false, try to scroll to the fragment for document.
At this point scripts may run for the newly-created document document.
Otherwise, if documentsEntryChanged is false and doNotReactivate is false, then:
...
3.6. Navigating to a Text Fragment
-
Let commonAncestor be nodeA.
-
While commonAncestor is non-null and is not a shadow-including inclusive ancestor of nodeB, let commonAncestor be commonAncestor’s shadow-including parent.
-
Return commonAncestor.
-
If node is a shadow root, return node’s host.
-
Otherwise, return node’s parent.
3.6.1. Finding Ranges in a Document
At a high level, we take a fragment directive string that looks like this:
text=prefix-,foo&unknown&text=bar,baz
We break this up into the individual text directives:
text=prefix-,foo text=bar,baz
For each text directive, we perform a search in the document for the first instance of rendered text that matches the restrictions in the directive. Each search is independent of any others; that is, the result is the same regardless of how many other directives are provided or their match result.
If a directive successfully matches to text in the document, it returns a range indicating that match in the document. The invoke text directives steps are the high level API provided by this section. These return a list of ranges that were matched by the individual directive matching steps, in the order the directives were specified in the fragment directive string.
If a directive was not matched, it does not add an item to the returned list.
-
For each text directive directive of text directives:
-
If the result of running find a range from a text directive given directive and document is non-null, then append it to ranges.
-
-
Return ranges.
end can be null. If omitted, this is an "exact" search and the returned range will contain a string exactly matching start. If end is provided, this is a "range" search; the returned range will start with start and end with end. In the normative text below, we’ll call a text passage that matches the provided start and end, regardless of which mode we’re in, the "matching text".
Either or both of prefix and suffix can be null, in which case context on that side of a match is not checked. E.g. If prefix is null, text is matched without any requirement on what text precedes it.
:~:text=The quick,lazy dogwill fail to match in
<div>The<div> </div>quick brown fox</div> <div>jumped over the lazy dog</div>
because the starting string "The quick" does not appear within a single, uninterrupted block. The instance of "The quick" in the document has a block element between "The" and "quick".
It does, however, match in this example:
<div>The quick brown fox</div> <div>jumped over the lazy dog</div>
-
Let searchRange be a range with start (document, 0) and end (document, document’s length)
-
While searchRange is not collapsed:
-
Let potentialMatch be null.
-
If parsedValues’s prefix is not null:
-
Let prefixMatch be the the result of running the find a string in range steps with query parsedValues’s prefix, searchRange searchRange, wordStartBounded true and wordEndBounded false.
-
If prefixMatch is null, return null.
-
Set searchRange’s start to the first boundary point after prefixMatch’s start
-
Let matchRange be a range whose start is prefixMatch’s end and end is searchRange’s end.
-
Advance matchRange’s start to the next non-whitespace position.
-
If matchRange is collapsed return null.
This can happen if prefixMatch’s end or its subsequent non-whitespace position is at the end of the document. -
Assert: matchRange’s start node is a
Textnode.matchRange’s start now points to the next non-whitespace text data following a matched prefix. -
Let mustEndAtWordBoundary be true if parsedValues’s end is non-null or parsedValues’s suffix is null, false otherwise.
-
Set potentialMatch to the result of running the find a string in range steps with query parsedValues’s start, searchRange matchRange, wordStartBounded false, and wordEndBounded mustEndAtWordBoundary.
-
If potentialMatch is null, return null.
-
If potentialMatch’s start is not matchRange’s start, then continue.
In this case, we found a prefix but it was followed by something other than a matching text so we’ll continue searching for the next instance of prefix.
-
-
Otherwise:
-
Let mustEndAtWordBoundary be true if parsedValues’s end is non-null or parsedValues’s suffix is null, false otherwise.
-
Set potentialMatch to the result of running the find a string in range steps with query parsedValues’s start, searchRange searchRange, wordStartBounded true, and wordEndBounded mustEndAtWordBoundary.
-
If potentialMatch is null, return null.
-
Set searchRange’s start to the first boundary point after potentialMatch’s start
-
-
Let rangeEndSearchRange be a range whose start is potentialMatch’s end and whose end is searchRange’s end.
-
While rangeEndSearchRange is not collapsed:
-
If parsedValues’s end item is non-null, then:
-
Let mustEndAtWordBoundary be true if parsedValues’s suffix is null, false otherwise.
-
Let endMatch be the result of running the find a string in range steps with query parsedValues’s end, searchRange rangeEndSearchRange, wordStartBounded true, and wordEndBounded mustEndAtWordBoundary.
-
If endMatch is null then return null.
-
-
Assert: potentialMatch is non-null, not collapsed and represents a range exactly containing an instance of matching text.
-
If parsedValues’s suffix is null, return potentialMatch.
-
Let suffixRange be a range with start equal to potentialMatch’s end and end equal to searchRange’s end.
-
Advance suffixRange’s start to the next non-whitespace position.
-
Let suffixMatch be result of running the find a string in range steps with query parsedValues’s suffix, searchRange suffixRange, wordStartBounded false, and wordEndBounded true.
-
If suffixMatch is null then return null.
If the suffix doesn’t appear in the remaining text of the document, there’s no possible way to make a match. -
If suffixMatch’s start is suffixRange’s start, return potentialMatch.
-
If parsedValues’s end item is null then break;
If this is an exact match and the suffix doesn’t match, start searching for the next range start by breaking out of this loop without rangeEndSearchRange being collapsed. If we’re looking for a range match, we’ll continue iterating this inner loop since the range start will already be correct. -
Set rangeEndSearchRange’s start to potentialMatch’s end.
Otherwise, it is possible that we found the correct range start, but not the correct range end. Continue the inner loop to keep searching for another matching instance of rangeEnd.
-
-
If rangeEndSearchRange is collapsed then:
-
-
Return null
-
While range is not collapsed:
-
Let node be range’s start node.
-
Let offset be range’s start offset.
-
If node is part of a non-searchable subtree or if node is not a visible text node or if offset is equal to node’s length then:
-
Set range’s start node to the next node, in shadow-including tree order.
-
Set range’s start offset to 0.
-
-
If the substring data of node at offset offset and count 6 is equal to the string " " then:
-
Add 6 to range’s start offset.
-
-
Otherwise, if the substring data of node at offset offset and count 5 is equal to the string " " then:
-
Add 5 to range’s start offset.
-
-
Otherwise:
-
Let cp be the code point at the offset index in node’s data.
-
If cp does not have the White_Space property set, return.
-
Add 1 to range’s start offset.
-
-
The basic premise of this algorithm is to walk all searchable text nodes within a block, collecting them into a list. The list is then concatenated into a single string in which we can search, using the node list to determine offsets with a node so we can return a range.
Collection breaks when we hit a block node, e.g. searching over this tree:
<div> a<em>b</em>c<div>d</div>e </div>
Will perform a search on "abc", then on "d", then on "e".
Thus, query will only match text that is continuous (i.e. uninterrupted by a block-level container) within a single block-level container.
-
While searchRange is not collapsed:
-
Let curNode be searchRange’s start node.
-
If curNode is part of a non-searchable subtree:
-
Set searchRange’s start node to the next node, in shadow-including tree order, that isn’t a shadow-including descendant of curNode.
-
Set searchRange’s start offset to 0.
-
-
If curNode is not a visible text node:
-
Set searchRange’s start node to the next node, in shadow-including tree order, that is not a doctype.
-
Set searchRange’s start offset to 0.
-
-
Let blockAncestor be the nearest block ancestor of curNode.
-
While curNode is a shadow-including descendant of blockAncestor and the position of the boundary point (curNode, 0) is not after searchRange’s end:
-
If curNode has block-level display then break.
-
If curNode is search invisible:
-
Set curNode to the next node, in shadow-including tree order, that isn’t a shadow-including descendant of curNode.
-
-
If curNode is a visible text node then append it to textNodeList.
-
Set curNode to the next node in shadow-including tree order.
-
-
Run the find a range from a node list steps given query, searchRange, textNodeList, wordStartBounded and wordEndBounded as input. If the resulting range is not null, then return it.
-
If curNode is null, then break.
-
Assert: curNode follows searchRange’s start node.
-
Set searchRange’s start to the boundary point (curNode, 0).
-
-
Return null.
A node is search invisible if it is an element in the HTML namespace and meets any of the following conditions:
-
The computed value of its display property is none.
-
If the node serializes as void.
-
Is any of the following types:
HTMLIFrameElement,HTMLImageElement,HTMLMeterElement,HTMLObjectElement,HTMLProgressElement,HTMLStyleElement,HTMLScriptElement,HTMLVideoElement,HTMLAudioElement -
Is a
selectelement whosemultiplecontent attribute is absent.
A node is part of a non-searchable subtree if it is or has a shadow-including ancestor that is search invisible.
A node is a visible text node if it is a Text node, the computed value of its parent element's visibility property is visible, and it is being rendered.
A node has block-level display if it is an element and the computed value of its display property is any of block, table, flow-root, grid, flex, list-item.
-
Let curNode be node.
-
While curNode is non-null
-
If curNode is not a
Textnode and it has block-level display then return curNode. -
Otherwise, set curNode to curNode’s parent.
-
-
Return node’s node document's document element.
Text nodes nodes, and booleans wordStartBounded and wordEndBounded, follow these steps:
-
When requiring a word boundary at the beginning, it will not match in “color orange”.
-
When requiring a word boundary at the end, it will not match in “forest ranger”.
See § 3.6.2 Word Boundaries for details and more examples.
-
Let searchBuffer be the concatenation of the data of each item in nodes.
data is not correct here since that’s the text data as it exists in the DOM. This algorithm means to run over the text as rendered (and then convert back to Ranges in the DOM). [Issue #WICG/scroll-to-text-fragment#98]
-
Let searchStart be 0.
-
If the first item in nodes is searchRange’s start node then set searchStart to searchRange’s start offset.
-
Let start and end be boundary points, initially null.
-
Let matchIndex be null.
-
While matchIndex is null
-
Set matchIndex to the index of the first instance of queryString in searchBuffer, starting at searchStart. The string search must be performed using a base character comparison, or the primary level, as defined in [UTS10].
Intuitively, this is a case-insensitive search also ignoring accents, umlauts, and other marks. -
If matchIndex is null, return null.
-
Let endIx be matchIndex + queryString’s length.
endIx is the index of the last character in the match + 1. -
Set start to the boundary point result of get boundary point at index matchIndex run over nodes with isEnd false.
-
Set end to the boundary point result of get boundary point at index endIx run over nodes with isEnd true.
-
If wordStartBounded is true and matchIndex is not at a word boundary in searchBuffer, given the language from start’s node as the locale; or wordEndBounded is true and matchIndex + queryString’s length is not at a word boundary in searchBuffer, given the language from end’s node as the locale:
-
Set searchStart to matchIndex + 1.
-
Set matchIndex to null.
-
-
-
Let endInset be 0.
-
If the last item in nodes is searchRange’s end node then set endInset to (searchRange’s end node's length − searchRange’s end offset)
endInset is the offset from the last position in the last node in the reverse direction. Alternatively, it is the length of the node that’s not included in the range. -
If matchIndex + queryString’s length is greater than searchBuffer’s length − endInset return null.
If the match runs past the end of the search range, return null. -
Assert: start and end are non-null, valid boundary points in searchRange.
Text nodes nodes, and a boolean isEnd, follow these steps:
This is a small helper routine used by the steps above to determine which node a given index in the concatenated string belongs to.
isEnd is used to differentiate start and end indices. An end index points to the "one-past-last" character of the matching string. If the match ends at node boundary, we want the end offset to remain within that node, rather than the start of the next node.
-
Let counted be 0.
-
For each curNode of nodes:
-
Let nodeEnd be counted + curNode’s length.
-
If isEnd is true, add 1 to nodeEnd.
-
If nodeEnd is greater than index then:
-
Return the boundary point (curNode, index − counted).
-
-
Increment counted by curNode’s length.
-
-
Return null.
3.6.2. Word Boundaries
A word boundary is defined in [UAX29] in Unicode Text Segmentation § Word_Boundaries. Unicode Text Segmentation § Default_Word_Boundaries defines a default set of what constitutes a word boundary, but as the specification mentions, a more sophisticated algorithm should be used based on the locale.
Dictionary-based word bounding should take specific care in locales without a word-separating character. E.g. In English, words are separated by the space character (' '); however, in Japanese there is no character that separates one word from the next. In such cases, and where the alphabet contains fewer than 100 characters, the dictionary must not contain more than 20% of the alphabet as valid, one-letter words.
A locale is a string containing a valid [BCP47] language tag, or the empty string. An empty string indicates that the primary language is unknown.
A substring is word bounded in a string text, given locales startLocale and endLocale, if both the position of its first character is at a word boundary given startLocale, and the position after its last character is at a word boundary given endLocale.
A number position is at a word boundary in a string text, given a locale locale, if, using locale, either a word boundary immediately precedes the positionth code unit, or text’s length is more than 0 and position equals either 0 or text’s length.
In languages with a word separator (e.g. " " space) this is (mostly) straightforward; though there are details covered by the above technical reports such as new lines, hyphenations, quotes, etc.
Some languages do not have such a separator (notably, Chinese/Japanese/Korean). Languages such as these requires dictionaries to determine what a valid word in the given locale is.
Text fragments are restricted such that match terms, when combined with
their adjacent context terms, are word bounded. For example, in an
exact search like prefix,start,suffix, "prefix+start+suffix" will match only if the entire result is word bounded. However, in a
range search like prefix,start,end,suffix, a match is
found only if both "prefix+start" and "end+suffix" are
word bounded.
The goal is that a third-party must already know the full tokens they are
matching against. A range match like start,end must be
word bounded on the inside of the two terms; otherwise a third party could
use this repeatedly to try and reveal a token (e.g. on a page with "Balance: 123,456 $", a third-party could set prefix="Balance: ", end="$" and vary start to try and guess the numeric token one digit at a time).
For more details, refer to the Security Review Doc
3.7. Indicating The Text Match
The UA may choose to scroll the text fragment into view as part of the try to scroll to the fragment steps or by some other mechanism; however, it is not required to scroll the match into view.
The UA should visually indicate the matched text in some way such that the user is made aware of the text match, such as with a high-contrast highlight.
The UA should provide to the user some method of dismissing the match, such that the matched text no longer appears visually indicated.
The exact appearance and mechanics of the indication are left as UA-defined. However, the UA must not use any methods observable by author script, such as the Document’s selection, to indicate the text match. Doing so could allow attack vectors for content exfiltration.
The UA must not visually indicate any provided context terms.
Since the indicator is not part of the document’s content, UAs should consider ways to differentiate it from the page’s content as perceived by the user.
3.7.1. URLs in UA features
UAs provide a number of consumers for a document’s URL (outside of programmatic
APIs like window.location). Examples include a location bar
indicating the URL of the currently visible document, or the URL used when a
user requests to create a bookmark for the current page.
To avoid user confusion, UAs should be consistent in whether such URLs include the fragment directive. This section provides a default set of recommendations for how UAs can handle these cases.
We provide these as a baseline for consistent behavior; however, as these features don’t affect cross-UA interoperability, they are not strict conformance requirements.
Exact behavior is left up to the implementing UA which can have differing constraints or reasons for modifying the behavior. e.g. UAs can allow users to configure defaults or expose UI options so users can choose whether they prefer to include fragment directives in these URLs.
It’s also useful to allow UAs to experiment with providing a better experience. E.g. perhaps the UA’s displayed URL can elide the text fragment if the user scrolls it out of view?
The general principle is that a URL should include the fragment directive only while the visual indicator is visible (i.e. not dismissed). If the user dismisses the indicator, the URL should reflect that by also removing the the fragment directive.
If the URL includes a text fragment but a match wasn’t found in the current page, the UA may choose to omit it from the exposed URL.
A text fragment that isn’t found on the page can be useful information to surface to a user to indicate that the page has changed since the link was created.
However, it’s unlikely to be useful to the user in a bookmark.
A few common examples are provided below.
3.7.1.1. Location Bar
The location bar’s URL should include a text fragment while it is visually indicated. The fragment directive should be stripped from the location bar URL when the user dismisses the indication.
It is recommended that the text fragment be displayed in the location bar’s URL even if a match wasn’t located in the document.
3.7.1.2. Bookmarks
Many UAs provide a "bookmark" feature allowing users to store a convenient link to the current page in the UA’s interface.
A newly created bookmark should, by default, include the fragment directive in the URL if, and only if, a match was found and the visual indicator hasn’t been dismissed.
Navigating to a URL from a bookmark should process a fragment directive as if it were navigated to in a typical navigation.
3.7.1.3. Sharing
Some UAs provide a method for users to share the current page with others, typically by providing the URL to another app or messaging service.
When providing a URL in these situations, it should include the fragment directive if, and only if, a match was found and the visual indicator hasn’t been dismissed.
3.8. Document Policy Integration
This specification defines a configuration point in Document Policy with name "force-load-at-top". Its type is boolean with default value false.
https://example.com#:~:text=foo. The
example.com server response includes the header:
Document-Policy: force-load-at-top
When the page loads, the element containing "foo" will be marked as the indicated part and set as the document’s target element. However, "foo" will not be scrolled into view.
Fragment-based scroll blocking from this policy is specified in an amendment to the scroll to the fragment algorithm in the § 3.6 Navigating to a Text Fragment section of this document.
History scroll restoration is blocked by amending the restore persisted state steps by inserting a new step after 2:
-
Get the document policy value of the "force-load-at-top" feature for the Document. If the result is true, then the user agent should not restore the scroll position for the Document or any of its scrollable regions.
3.9. Feature Detectability
For feature detectability, we propose adding a new FragmentDirective interface
that is exposed via document.fragmentDirective if the UA supports
the feature.
[Exposed =Window ]interface { };FragmentDirective
We amend the Document interface to include a fragmentDirective property:
partial interface Document { [SameObject ]readonly attribute FragmentDirective ; };fragmentDirective
This object may be used to expose additional information about the text fragment or other fragment directives in the future.
4. Generating Text Fragment Directives
This section contains recommendations for UAs automatically generating URLs with a text directive. These recommendations aren’t normative but are provided to ensure generated URLs result in maximally stable and usable URLs.
4.1. Prefer Exact Matching To Range-based
The match text can be provided either as an exact string "text=foo%20bar%20baz" or as a range "text=foo,bar".
Prefer to specify the entire string where practical. This ensures that if the destination page is removed or changed, the intended destination can still be derived from the URL itself.
The first recorded idea of using digital electronics for computing was the 1931 paper "The Use of Thyratrons for High Speed Automatic Counting of Physical Phenomena" by C. E. Wynn-Williams.
We could create a range-based match like so:
https://en.wikipedia.org/wiki/History_of_computing#:~:text=The%20first%20recorded,Williams
Or we could encode the entire sentence using an exact match term:
The range-based match is less stable, meaning that if the page is changed to include another instance of "The first recorded" somewhere earlier in the page, the link will now target an unintended text snippet.
The range-based match is also less useful semantically. If the page is changed to remove the sentence, the user won’t know what the intended target was. In the exact match case, the user can read, or the UA can surface, the text that was being searched for but not found.
Range-based matches can be helpful when the quoted text is excessively long and encoding the entire string would produce an unwieldy URL.
Text snippets shorter than 300 characters are encouraged to be encoded using an exact match. Above this limit, the UA can encode the string as a range-based match.
4.2. Use Context Only When Necessary
Context terms allow the text directive to disambiguate text snippets on a page. However, their use can make the URL more brittle in some cases. Often, the desired string will start or end at an element boundary. The context will therefore exist in an adjacent element. Changes to the page structure could invalidate the text directive since the context and match text will no longer appear to be adjacent.
<div class="section">HEADER</div> <div class="content">Text to quote</div>
We could craft the text directive as follows:
text=HEADER-,Text%20to%20quote
However, suppose the page changes to add a "[edit]" link beside all section headers. This would now break the URL.
Where a text snippet is long enough and unique, a UAs are encouraged to avoid adding superfluous context terms.
Use context only if one of the following is true:
- The UA determines the quoted text is ambiguous
- The quoted text contains 3 or fewer words
4.3. Determine If Fragment Id Is Needed
When the UA navigates to a URL containing a text directive, it will fallback to scrolling into view a regular element-id based fragment if it exists and the text fragment isn’t found.
This can be useful to provide a fallback, in case the text in the document changes, invalidating the text directive.
The earliest known tool for use in computation is the Sumerian abacus
By specifying the section that the text appears in, we ensure that, if the text is changed or removed, the user will still be pointed to the relevant section:
However, UAs should take care that the fallback element-id fragment is the correct one:
By the late 1960s, computer systems could perform symbolic algebraic manipulations
Even though the current URL of the page is: https://en.wikipedia.org/wiki/History_of_computing#Early_computation, using #Early_computation as a fallback is inappropriate. If the above sentence is changed or removed, the page will load in the #Early_computation section which could be quite confusing to the user.
If the UA cannot reliably determine an appropriate fragment to fallback to, it should remove the fragment id from the URL: